

It is often dramatically and pathetically argued that it is better not to create technical debt. Yes, it is better without it, of course. But the consequences can still be eliminated.
I refer to technical debt as all changes and improvements, infrastructural modifications and process changes, changes in team structures aimed at eliminating gaps (made consciously or not within the framework of launching products), and features that greatly interfere over time.
And since such things cannot be fixed without a firm and confident teamplay of the production and operations departments, this story is directly about DevOps.
Technical Debt – Whose Is It?
But first, the root of the problem – why am I even talking about technical debt? Because I am very offended that business does not allocate time for it. This red thread runs through all reports, meetups, and communications between developers and operations.
Evil, bad, terrible business does not allocate time to work with technical debt. Even a righteous question arises: “Don’t they need quality at all?” Looking ahead, I will say: “Nobody needs quality.” But I will reveal this thought a little later.
To analyze this situation, let’s consider why business does this to us. And to get an answer, we need to think about whose is technical debt. Who is responsible for it?

After years of involvement, I realized we were like Frodo, who offered everyone a ring. It is like, “Help me carry this burden!” We are waiting for businesses to want (exactly want) us to deal with technical debt. But the root cause of our mutual misunderstanding with business is that it will never want to.
For us, it’s an engineering challenge, a way to improve product excellence, or even a mechanism to increase pride in our product. But for business, it’s always a nuisance, a necessary evil (or necessity) that you must spend time on.
Imagine you get into a cab, and the driver asks, “Can I stop at the car wash?

The business in this situation is a client, and the developers is the cab driver.
- The business is indignant: “How come?! I’m paying for travel time, and you’re going to the car wash!”
- To which the cab driver reasonably replies: “Don’t you want to ride in a clean car that smells good?”
- The business answers: “Man, of course I do! But I expect it by default, and I’m not ready to stop at the car wash now for the sake of it!”
This is how businesses treat technical debt. It is like a suggestion to stop by a car wash. I choose the appropriate category when ordering a cab to have a clean or luxury salon. At the ordering stage, I’m willing to invest in it, but stopping by the car wash is not.
Because, as I said earlier, no one wants quality. But it is expected by default.
It’s a must. Businesses can’t resign themselves to not going to the car wash, and businesses can’t go there at the expense of their own time. So what do we do? A business is a locomotive. It needs features, sales, and customers. It is impossible to sell the technical debt to a business through our “I want” and “I wish.” But it is possible to motivate business in another way.
In the course of my journey, I have formed 3 categories of business motivation for “buying” technical debt:
- “Fat” indifference. When there’s a rich investor, the CEO can afford the development team of weird geeks. It is like, “Well, let them do it! The main thing is to get the product done, and the team spirit is wow, everything is cool, and we’d be the best office in the world”.
In my view, it’s a cool freestyle that often leads to disaster because technical debt requires pragmatism. When we don’t do it pragmatically, we create a Leviathan of pseudo-cool architecture.
- Fear. This is one of the most effective, widespread, and efficient models for technical debt. What kind of “want” can we talk about here when it’s scary? It’s about when something happens like a client left because of a failure or a hack. And it’s all because of low quality, brakes, or something else. But bluntly selling through fear is also bad. Speculation with fear works against trust. You need to sell carefully and as honestly as possible.
- Trust. It is when a business gives you as much time as you need to work on technical debt. Trust works and is preserved only when you are carefully small to the total share and as pragmatic as possible in taking this time. Otherwise, trust is destroyed. Moreover, it does not accumulate. A constant process goes in waves: trust increases and then fades.
Next, I’ll discuss my experience and what’s working for me and my awesome team.
How Deep Is the Rabbit Hole With Technical Debt?
When I joined the new company 3 years ago, I needed to understand how much this technical debt was. I knew that it existed from the statistics of requests, including those from businesses and partners. I needed to figure out what I was dealing with in general.
This is a normal and obligatory first step in working with technical debt. You should not rush to do the first thing you find. You should analyze the situation as a whole.
Based on what I saw then, I had an assumption that one of the root problems is a large code coupling. Now, I involve everyone less in this process, but back then, I gathered the entire production team to fix what layers we wanted to emphasize in our application suite.
Our application had at least 80 different components (distributions, not installations). After figuring out the situation, it had to be dealt with.
Phase 1. Virtual Teams
Being so clever, I came up with the idea that I would pretend everyone had time and formed a virtual team around each component. It looked like, “Guys, who will take on which component? Form your suggestions on how to improve it.” But to stay focused, we all together formulated the criteria for optimizing the first phase:
- Loose coupling
- Cost-effective scalability
- Easy connection of new developers (simple and clear principles: what exactly can be done in this component and what can’t, plus isolation of code that can’t be “touched” by everyone)
- Ability to use an external API where it is needed
- Accessibility of the proposed technology stack
- QuickWin optimizations in current solutions
- Ease of monitoring and troubleshooting
- Audit + license purity principles
- Versioning and obsolescence principles
Of course, this was not a focus but a set of criteria for almost all aspects of software development. The whole list can be replaced by one phrase: “Fix everything.”
This phase ended in a fiasco, in the sense that simply nothing happened. We made very little progress implementing some things because I was trying to plan them through a shared backlog. The tasks were incomprehensible. They were put into work manually. I quickly realized that it was hard on both me and the team, plus conflicts and arguments were constantly growing.
So, I moved on to phase 2.
Phase 2. Technical Debt Is Mine
In phase 1, I agreed with the CEO of our company that we would introduce a backlog quota. We would spend 70% on business issues, 15% on defect elimination, and 15% on the technical debt.
Second, in the previous phase, I realized that if everyone is responsible for an issue, no one is responsible for that issue. This is not a turquoise statement at all. I don’t like it myself. But the opposite requires a very high level of maturity and teamwork. That’s why I decided to form a system of technical leaders.
But I didn’t just appoint a person to be the technical leader of a component. I laid out my expectations as much as possible, defined their development path, and made them responsible for the situation on production. The OPS experts are not awake if your component is messing up on production. It’s you who are trying to solve the situation.
And so we set off. There are technical leaders (those in charge) and a 15% quota for technical debt (there is time). But what did the reality look like in the end?
The first thing we encountered was that we have FinTech, compliance, and segregation of duties, i.e., I and development have no access to production and cannot have it by definition. And yet, I say, “Guys, you are responsible for the situation at production!”
Give People the Logs!
When you give people responsibility, please give them a tool in their hands. And that’s the first thing we did with the OPS experts, providing logs to the technicians so they could see the logs of their components.
And we had a really collaborative effort – our first step towards DevOps, where operations and development work together. Exploitation set up the log transfer (Kibana, etc.), while development had to ensure that the logs did not contain sensitive information (personal data, etc.).
5% Is Considered Lucky…

The reality is that despite the 15% quota, there are some business crises and urgent injections in every sprint because “The partner needs it now, or he will leave!” Of course, this technical debt is first pushed out of the sprint – as a result, we had sprints with 0%.
There were also sprints with 15%, but we had only 5-8% of technical debt on average. This is a big problem because a programmer cannot know how much time he will have for implementation.
For my part, I tried to help this situation by tirelessly flying a kite over all the teams. We learned to collect detailed metrics for each sprint, and I looked at the sprint at the end.
Sprint hacking is when the technical debt quota is systematically violated. If the quota is not met in one sprint, it doesn’t mean that everything is bad. Indeed, there are different situations, and you need to be flexible.
But when it was systematically repeated, I gathered the production experts, argued, and explained how important and unacceptable it was because the quota was agreed upon. It was my daily work to move the process in that model.
And it did move, but now I believe this approach has its own significant shortcomings.
Limitations of the Approach

Product owners are used to the fact that the backlog is all theirs and all tasks are coordinated by them: “Quota is good, but only we decide what the team will do in this quota of technical debt!”
And when developers came up with tasks (remember about strong connectivity) like refactoring, eliminating boilerplates, etc., they got a logical reaction: “What?! What boilerplate? What are we talking about?!”
As a result, tasks were substituted by those that could be referred to as technical debt but were conditionally beneficial to the vendor. That’s why I had to take a tough stance and say: “Technical debt is mine! And I claim that it will be included in the technical debt of each product team in the quota of technical debt for each sprint.”
That’s how we lived. Although we lived and worked normally, the distrust grew stronger. When we do something and don’t tell anyone what it is, and the time is not spent on business tasks, it is unclear to everyone what result we bring.
Since the stats on technical debt quota utilization were skyrocketing, we faced the fact that we couldn’t do large projects. In addition, big projects often require multiple teams. This was also impossible because each product team is focused on its product and lives in its realities. It is impossible to dock them on a complex topic.
Also, no one included operations in the sprints. They don’t have sprints and backlogs like production. They are swamped with tasks with production, but that wasn’t included in the overall plans. And when development came with something done within those small pieces of technical debt to roll out to production, it could stay in OPS’s requests for quite a long time.
Because they really had no time, were loaded with additional tasks, and were prevented from working.
But despite this approach’s negative aspects, we achieved quite a lot.
What Have We Achieved With This Approach?

First, we have built up the muscle mass of autotests. By substantially redesigning the entire CI process, we made it a civilized process that we are not ashamed of.
Secondly, we successfully implemented the fight against spaghetti code in many components.
We have made modularization and reduced boilerplates. These tasks cannot be sold to the business even through fear. If the technology gaps in your product contain these problems and you need to fix them (if they are there, they need to be done first), you don’t even need to try to sell them. It can only be done through the “Technical debt – it’s mine” model, only through quota.
I have seen many attempts and tried to do it differently myself in the first phase. It didn’t work out.
Indeed, working in this mode cannot last for a long time. It’s a limited carte blanche that management gives you, trusting you as CTO and team leader.
Phase 3. Legitimate Project
Then, we initiated phase 3 – a “legitimate” project to work on technical debt. The assumption was that we were moving away from a closed quota, planning through a common product backlog (i.e., the product owners accept that these projects need to be done), and going to a clean sale. To make this happen, we did 2 things:
- I narrowed down as much as possible the scope of work that we started to do within the framework of this project.
- I formed concrete expectations about what we will fight for in production. It was a complete rejection of idealism because our tasks should be as pragmatic as possible, understandable, and useful to the service from a business point of view.
An important point is that we have a certain illusion that we are trying to calculate the business value of technical debt, although this is rarely possible. And if it can still be calculated, then we have a nightmare technical debt!
Positive value works better for business than negative value. If you say, “This client will leave. He brings in so much money,” then until he leaves, it won’t work. It’s not a business value. Moreover, the culture of working with risks is still not very high, so the mode is: “No loss until they leave.”
It is also not necessary to show business value. Where you can show it, but you can show the technological value, only it must be calculated.
Guide on How to Sell Technical Debt
Here is the entire workflow of this phase for selling technical debt.
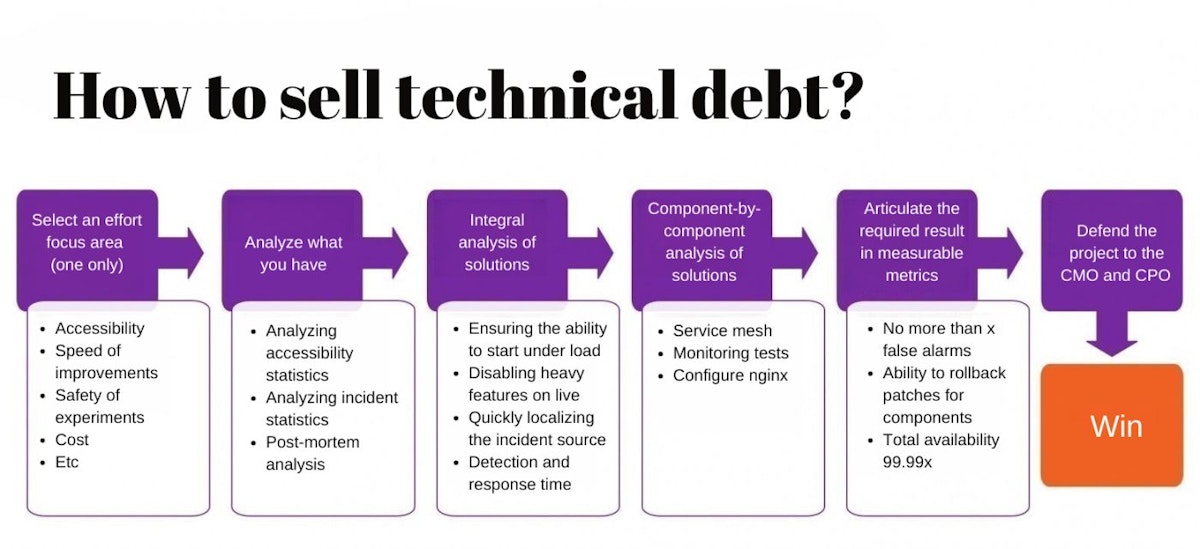
Choose an Area of Focus (Just One)
Since this is selling through fear, choose an area that really affects your business. The areas can be different: availability, speed of rework, safety of A/B tests and experiments, and cost of rework. There is a huge number of areas and topics.
In my case, I chose accessibility because it was on the radar of the business and had some impact on our service. It is vital not to spread yourself thin and choose only one topic.
Do Integral Analysis
I analyzed the availability and incident statistics for the year and detailedly analyzed all postmortems for all situations that occurred throughout the year. After that, I formed a top-level understanding of what we need to work on as much as technically possible, but again – substantively.
The first rule of availability is not to try to build a system that will always be available but to be ready when an incident occurs. That’s what we have to ensure.
The second issue and basic rule of availability is the degradation agreement: something is bound to happen someday, and you must be prepared to preserve your service, perhaps at the cost of giving up some functionality you provide. This agreement has to be maintained, including at the program level.
The third issue concerns monitoring and observability. This is the rapid localization of incident sources and response detection time. If you have a lot of flaky tests, you will have to stop trusting your monitoring. If your production tests have instructions for service desk reactions like, “If it hasn’t gone out in 5 minutes, call me” – you’re not monitoring the production situation. The test should be as unambiguous as possible: “It shows – it means there’s trouble somewhere, let’s go!”
Do Component-by-Component Analysis
For this purpose, we have formed what exactly we will do for each direction and component. We mean where we will drag service mesh in, how we will shake up monitoring, and based on what. Here, we have listed about 15%, but in fact, there are a lot of program improvements.
We’ve laid it all out, but it’s not marketable yet. To go out and show it openly now, we have done the following for each project of this phase.
Formulate Substantive, Quantitative Indicators
We are very afraid of quantitative indicators: how can we measure the quality of developers’ work in quantitative indicators? We have a lot of arguments against quantitative indicators, but we should not take them head-on.
Value should not be taken only as business value. They can be phrased, for example, as “no more than X false positives.”
You can list a specific set of components for which it is critical to provide canary releases or the ability to ensure guaranteed patch rollback. Overall availability should, of course, be a quantitative indicator. It’s a must.
Defending the Projects
With this set of pragmatic projects, as clear as possible metrics and the results we need to achieve, I said: “Guys, I need a quota of technical debt. I need you to include these projects in your pool to accelerate them so that they go into the overall planning on a fully legal basis together with the business objectives.”
It was heard, we did it, and it worked. I think it’s like the video on how to draw an owl: “Draw an oval and two dashes.” At the end – magic – you get an owl! But all the magic is that you have to nail this whole project and get it to the end.
Not just to do some things in this direction but to bring it to the result. That is, to reach the stated quantitative indicators and show them. This abyss cannot be jumped 95% of the time. It must be jumped completely.
Advantages of the Approach
So, we started jumping (over the abyss). We are doing it successfully. Now, we are on the second round of this project. That is, we have dragged the first pool of projects and agreed on the second pool of projects. What has changed?
Increasing Trust
Trust is powerfully increased through openness if we show real, quantifiable metrics. But the truth is, technical debt sale comes in through fear. This step can’t be avoided. But you don’t have to be afraid or ashamed of it either. The main thing is not to speculate on fear but to really analyze it, as I have shown in different phases (integral analysis, component-by-component analysis).
Doing Big Projects
Since these are now legitimized projects, we can synchronize across teams and do really big projects. Some projects were done sequentially from sprint to sprint. We are tracked regularly (once a week) within that project by the composition of the technology team and understand who is where (in what phase).
This information is as open and transparent as possible. The progress of projects and current statuses are published and available to product owners (and anyone else who wants to see it).
OPS’ers in the Project
Most importantly, we realized that we had a lot of things to redesign in the infrastructure and the rollout process. OPS’ers were explicitly included in this project.
In my mind, this is more DevOps than Kubernetes and Docker when OPS’ers discuss with developers how to change the architecture of a component, and developers discuss with OPS’ers how best to change the infrastructure.
Why Didn’t I Do It Right Away?
Here we come back to what I was talking about at the end of phase 2: it wouldn’t have worked before. Because what we did in Phase 2 (spaghetti code that we redesigned, that muscle-building of tests, and the redesign of CI processes) would have been impossible to sell to the business regarding measurable metrics.
That situation wasn’t mapped to any particular fear, and our standard argument, “We’re taking a long time to code because spaghetti code” – no one in the business listens. So, we wouldn’t have been able to drag through that approach.
From my point of view, if you have a technology platform that requires such deep infrastructural rework, you can’t avoid phase 2.
You have to go for it, but you have to be ready not only to flutter around like a kite all the time but also to shut this shop down quickly enough not to lose the trust of your business.
This article was originally published by Sofia Konobievska on Hackernoon.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}