
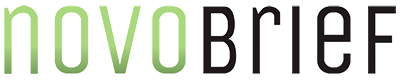

Enterprise artificial intelligence has hit a wall. As we move through 2026, over 70% of enterprise generative AI initiatives have been quietly stalled, scaled back, or abandoned entirely. This failure rate is not driven by limitations within large language models (LLMs) or a lack of algorithmic sophistication. The bottleneck is systemic: severe structural gaps within legacy data architecture that standard infrastructure migration cannot fix.
For the past several years, organizations rushed to migrate their on-premises workloads to public cloud infrastructure. They operated under a deeply flawed assumption: that moving data to a modern cloud provider automatically makes that data ready for AI. It does not.
A basic “lift-and-shift” operation merely changes the hosting zip code of existing technical debt. Relational databases designed for localized, historical transactional reporting cannot scale to handle the massive processing demands, multimodal ingestion, and sub-second latencies required by real-time agentic workflows and retrieval-augmented generation (RAG).
To build an agile, cognitive enterprise, organizations must look beyond basic cloud modernization and focus heavily on deliberate data modernization in the cloud.
Cloud Migration vs. Cloud Data Modernization
| Simple Cloud Migration | Cloud Data Modernization |
| Rehosts existing database structures Moves legacy schemas and technical debt directly to cloud servers without structural changes. | Unifies data into open Lakehouse Transforms data structures into modern, open table formats (e.g., Iceberg, Delta) to eliminate silos. |
| Focuses on infrastructure cost shift Mainly an operational expense shift from on-premises hardware to cloud consumption. | Focuses on data product readiness Treats data as an internal product, focusing on high availability, discovery, and value creation. |
| Preserves traditional batch silos Keeps data isolated within traditional, slow-moving batch processing pipelines. | Enables real-time streaming & mesh Decentralizes data ownership across domains using high-velocity, event-driven pipelines. |
| Incompatible with real-time AI context Static data layers cannot provide the low latency or context needed for active AI models. | Purpose-built for LLMs & RAG systems Engineered to feed clean, context-rich vector and structured data directly into GenAI and agentic workflows. |
True data platform modernization represents a complete structural evolution. It marks an intentional transition away from monolithic, isolated data warehouses toward cloud-native Lakehouse architectures and decentralized data mesh environments. This is the only path to turning massive, inert data volumes from corporate liability into a stream of clean, highly optimized, and context-rich enterprise intelligence.
Why Data Modernization in the Cloud Matters for AI-Driven Enterprises
In a modern enterprise landscape, processing scale and speed are non-negotiable. Deploying an effective cloud data modernization strategy is now the definitive line dividing companies that successfully monetize AI from those bankrupting themselves on experimental proof-of-concepts.
The AI-Readiness Imperative
Raw data volume without structure, continuous validation, and discoverability is purely a financial drain. Generative AI models require highly contextualized, clean, and real-time structured data pipelines to deliver accurate outputs. Without complete data architecture modernization, feeding raw, uncurated enterprise data into LLMs yields hallucination-prone, risky systems. Enterprises need AI-ready data,information that is automatically cataloged, enriched with accurate metadata, and natively mapped to vector and graph spaces.
The Shift from Reports to Real-Time Intelligence
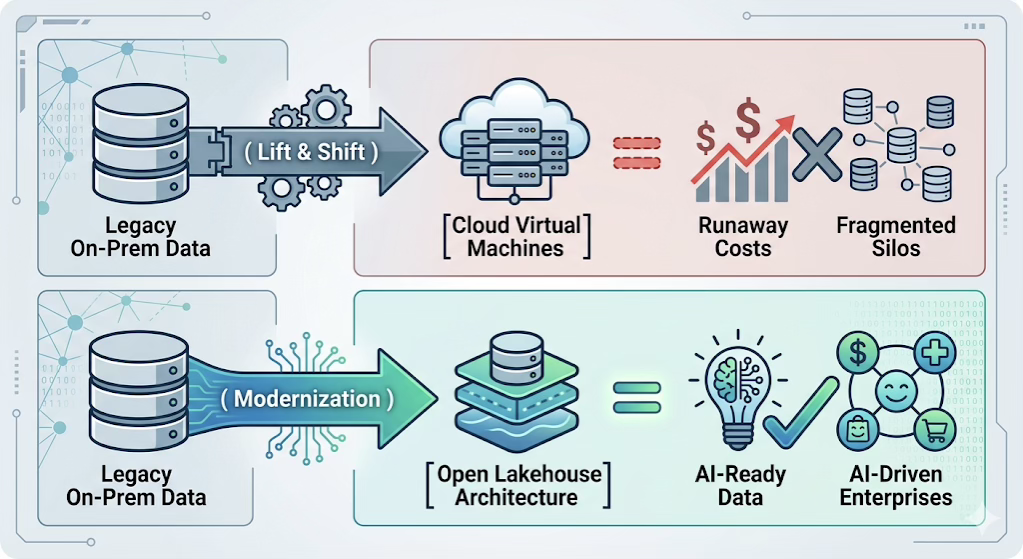
Traditional data pipelines were built for backward-looking data analytics modernization. They compiled weekly or monthly batch reports to review historical performance. Modern business demands real-time, streaming intelligence. Whether executing dynamic fraud prevention in banking, live supply chain routing in logistics, or contextual customer interventions in e-commerce, the modern data estate must ingest, transform, and expose data within milliseconds of creation.
Regulatory and Governance Boundaries
The regulatory landscape has adapted swiftly to the rise of automated decision-making. Global data compliance acts now penalize organizations that cannot audit their data lineage or control how enterprise information trains proprietary models. Modernization replaces manually managed security with automated, immutable data governance features built directly into the delivery pipeline.
TCO and FinOps Realities
Running unoptimized, legacy-style analytical queries within a consumption-based cloud ecosystem is a recipe for fiscal disaster. Without dedicated cloud data modernization solutions, unthrottled ad-hoc queries run by hundreds of data analysts can deplete an annual cloud budget in months. True modernization optimizes compute-to-storage ratios, keeping total cost of ownership (TCO) completely predictable.
The Rise of Data Products and Data Mesh
Modern enterprises are breaking down centralized data engineering bottlenecks by moving toward a decentralized data mesh framework. In this paradigm, individual business domains own their data assets entirely, packaging them as discoverable, documented, and highly secure internal “data products.”
The 6-Layer Cloud Data Modernization Framework
To systematically transform an enterprise data footprint into a high-performance engine for corporate intelligence, organizations must adopt a unified architectural blueprint. This 6-layer cloud data modernization framework isolates key data lifecycle tasks while ensuring high throughput and seamless interoperability.
1. Event-Driven Ingestion Layer
The baseline layer replaces rigid, batch-based ETL (Extract, Transform, Load) routines with real-time, event-driven streaming pipelines. Utilizing modern streaming architectures like Apache Kafka or AWS Kinesis, it securely captures high-velocity telemetry, application events, and transactional updates instantly from the edge.
2. Storage & Compute Layer (Open Lakehouse)
The core of modern infrastructure is a unified Lakehouse architecture. By combining the cost-effective storage properties of a data lake with the transactional reliability, ACID compliance, and schema enforcement of a traditional data warehouse, it completely breaks down legacy data silos. By using open table formats such as Apache Iceberg, Delta Lake, or Apache Hudi decoupled from proprietary storage, organizations can query identical underlying files concurrently using multiple specialized analytical engines.
3. Transformation & Data Product Layer
Raw ingested files must be cleaned, structured, and contextualized immediately. This layer leverages modern declarative engineering tools to transform disorganized data into curated data products. Data is enriched, mapped to semantic definitions, and stored in highly optimized tabular structures, making it immediately usable by end applications without requiring further processing.
4. Enterprise Governance & Metadata Layer
Governance must move away from static, bureaucratic documentation spreadsheets and into the active code path. This layer provides automated, AI-driven data cataloging, real-time sensitive data masking, and granular role-based access control. Every data point moving through the pipeline is tagged with immutable execution lineage, allowing compliance officers to track the journey of any data element back to its source system.
5. Consumption & AI Activation Layer
This layer exposes data products directly to consuming applications. Beyond standard business intelligence dashboards and operational applications, this layer features dedicated vector search databases and graph data structures. These systems serve context-rich enterprise data straight to LLMs via high-speed RAG pipelines, ensuring corporate AI agents make decisions based on accurate, real-time facts.
6. Data Observability & FinOps Layer
The final layer runs continuously across the entire ecosystem, providing deep operational oversight. It monitors data quality in real time, alerting engineering teams to schema drift or anomalies before compromised data reaches downstream models. Concurrently, it applies rigorous FinOps for data principles—tracking every dollar spent on processing, isolating inefficient query patterns, and programmatically halting runaway cloud spend.
A 7-Step Cloud Data Modernization Roadmap
Constructing an enterprise-grade data infrastructure requires a methodical, step-by-step implementation strategy that preserves business continuity.
Step 1: Discovery & Technical Debt Assessment
Begin by programmatically mapping the enterprise’s existing data footprint. Identify hidden shadow data systems, evaluate undocumented data dependencies, and quantify accumulated technical debt across legacy relational databases and file shares.
Deliverable: A comprehensive data dependency graph and an explicit target inventory for modernization.
Step 2: Business Case Realization & Value Mapping
Avoid modernizing technology purely for technology’s sake. Align individual architectural upgrades directly with explicit business outcomes and tangible AI initiatives. If the core business goal is reducing customer churn by 15%, prioritize modernizing the customer-360 data pipelines first.
Deliverable: A boardroom-ready financial justification document detailing estimated infrastructure TCO impact and projected AI project velocity gains.
Step 3: Target Architecture Definition
Design the concrete structural layout of the new data estate based on specific organizational needs. Determine whether a highly decentralized data mesh topology or a unified, multi-region open Lakehouse architecture best serves the company’s geographical and operational requirements.
Deliverable: Detailed logical and physical architectural schematics across all cloud layers.
Step 4: Engineering Pattern & Tool Selection
Select the core technical stack required to support the new target architecture. Evaluate open-source frameworks against native cloud provider solutions. Establish standard, repeatable engineering design patterns for data ingestion, schema validation, and real-time data orchestration.
Deliverable: A finalized, approved corporate technology stack register and a defined data engineering playbook.
Step 5: Wave-Based Migration Execution
Do not attempt a high-risk, single-day cutover. Group analytical workloads systematically into isolated migration waves based on complexity and business criticality. Migrate low-risk workloads first to validate core design patterns before moving high-visibility production workloads.
Deliverable: Successful execution of pilot waves with zero disruption to active business operations.
Step 6: Automated Quality Assurance & Parity Validation
Run the legacy and newly modernized data pipelines in parallel for a designated period. Utilize automated data observability tooling to continuously compare outputs, proving absolute data parity across schema, row counts, and complex calculations before decommissioning older infrastructure.
Deliverable: Formal engineering validation reports confirming identical pipeline outputs and performance improvements.
Step 7: Operationalization & The Data Product Culture Shift
Modern data engineering is a continuous discipline, not an isolated project. Re-skill legacy database administrators to operate within modern cloud data ecosystems. Establish cross-functional product teams centered around long-term data product ownership, officially launching the self-service enterprise platform.
Deliverable: A fully operational self-service data portal used actively by cross-functional business domains.
Choosing Your Cloud Platform: AWS vs. Azure vs. Google Cloud
Selecting the appropriate hyperscaler foundation requires a highly pragmatic assessment. Organizations must evaluate how each cloud vendor aligns with their existing investments, internal skill sets, and long-term artificial intelligence objectives.
| Capability Vector | Amazon Web Services (AWS) | Microsoft Azure | Google Cloud Platform (GCP) |
| Data Core Strengths | Immense ecosystem scale; mature decoupled object storage (S3); flexible processing frameworks (Glue, EMR, Redfish Serverless). | Direct enterprise integration; unified governance frameworks (Microsoft Purview); enterprise relational data dominance. | Market-leading analytics engine (BigQuery); native decoupling of compute/storage; advanced geospatial and streaming data handling. |
| Native AI Interoperability | Flexible multi-model access via Amazon Bedrock; high-throughput vector optimization for SageMaker pipelines. | Seamless, prioritized access to native OpenAI infrastructure and deep integrations with the Copilot ecosystem. | Cutting-edge native integration with the Gemini model ecosystem and advanced Vertex AI ML-Ops pipelines. |
| Ecosystem & Portability | Supports open-source ecosystems; high community support for Apache Iceberg and open open-source data orchestration. | Highly optimized for Windows-centric server software, SQL Server lifecycles, and modern PowerBI pipelines. | Strong historical foundations in containerized Kubernetes computing and multi-cloud analytics via Big Query Omni. |
| FinOps Sophistication | Highly granular pricing options; require careful, expert architecture configurations to avoid cost surprises. | Structured corporate discount programs; clear billing integration within Microsoft enterprise agreements. | Highly intuitive automated compute scaling; simpler, exceptionally predictable storage-to-query pricing mechanics. |
| Ideal-Fit Enterprise Scenario | Organizations seeking a highly mature, massively scalable platform with complete freedom over tool selection. | Heavily invested in Microsoft enterprises prioritizing unified governance and seamless OpenAI model access. | Highly analytical, data-centric companies run advanced machine learning models and high-velocity streaming. |
Common Challenges & Anti-Patterns (And How to Avoid Them)
Navigating complex data platform modernization initiatives exposes teams to recurring technical failure modes. Recognizing these anti-patterns early protects projects from failure.
The “Lift-and-Shift” Database Illusion
- The Failure: Rehosting an identical, unoptimized legacy data warehouse setup directly into cloud-hosted virtual machines. This retains the same performance bottlenecks while drastically increasing infrastructure expenses.
- Mitigation: Enforce a strict architectural policy: every legacy asset slated for cloud migration must undergo a modernization assessment. If a database does not fit in an open Lakehouse format or a decoupled data product model, restructure it before it touches cloud storage.
Passive, Bureaucratic Data Governance
- The Failure: Treating data governance as a static, backward-looking documentation chore. This forces engineers to bypass controls to ship pipelines on time, creating a shadow data ecosystem.
- Mitigation: Move governance entirely into the automated continuous deployment (CI/CD) pipeline. Use automated tools to discover sensitive schema changes, tag new columns with metadata, and enforce security policies programmatically at build time.
Ignoring the Consumer Product Metaphor
- The Failure: Building extensive, highly advanced multi-region data platforms without engaging the end business consumers who use the outputs. This results in incredibly expensive platforms that deliver zero actual business utility.
- Mitigation: Treat every data pipeline as a formal consumer product. Assign a dedicated product manager to work alongside data engineering teams, interviewing business users to define exact data schemas, documentation rules, and service-level objectives before writing pipeline code.
Running Blind Without FinOps Controls
- The Failure: Granting internal engineering teams unmonitored query privileges across a massive cloud data Lakehouse. This leads to accidental, complex queries that process petabytes of unindexed data, causing immediate cloud budget overruns.
- Mitigation: Deploy strict, automated programmatic cost limits. Implement automated query timeouts, partition all tabular data formats using columns like dates, and set up real-time billing alerts that immediately freeze non-critical processing instances if spending thresholds are breached.
Measuring Success: KPIs for Cloud Data Modernization
To justify large-scale modernization investments to executive leadership, organizations must measure performance using precise technical, operational, and financial metrics.
Technical Performance Metrics
- Query Latency Reduction: Track the execution speeds of standard enterprise analytical queries. Modernization should yield a significant speedup compared to legacy relational hardware.
- Data Freshness (Ingestion SLA): Measure the exact time elapsed between data generation at the source and its availability inside the ingestion layer. Aim to compress this window from days or hours to minutes or seconds.
- Storage-to-Compute Cost Ratio: Monitor processing costs by ensuring compute resources scale down completely to zero when idle, rather than running continuous server overhead.
Operational Efficiency Metrics
- Time-to-Market for New Pipelines: Track how many days or weeks it takes an engineering team to deploy a verified, secure data product pipeline into production from scratch.
- Data Quality Downtime Incidents: Monitor the frequency and duration of operational pipeline breakages caused by unexpected schema changes or bad source formatting.
- Self-Service Adoption Velocity: Measure the number of distinct business domains independently generating data products without relying on a centralized data team bottleneck.
Tangible Business Value Metrics
- AI Model Hallucination Rates: Track accuracy improvements in customer-facing generative AI and internal RAG applications driven by context-rich enterprise data.
- Time-to-Insight Acceleration: Quantify how quickly business units can run complex, cross-functional analytical queries to make strategic commercial pivots.
- Infrastructure TCO Reduction: Measure the long-term operational savings achieved by decommissioning expensive on-premises hardware maintenance contracts in favor of optimized cloud resource consumption.
Industry Use Cases for Cloud Data Modernization
Deploying dedicated data modernization services yields distinct competitive advantages across specific economic verticals.
BFSI (Banking, Financial Services, and Insurance)
Modernizing data infrastructure allows financial institutions to run real-time, streaming fraud detection models that evaluate millions of transactions per second. Additionally, it helps aggregate highly disparate customer accounts into secure, context-rich profiles, powering compliant, personalized AI financial advisory platforms.
Healthcare and Life Sciences
By breaking down traditional data silos between legacy electronic health records (EHRs), clinical imaging archives, and genomic sequencing databases, modernization enables medical centers to run multimodal research pipelines. This accelerates clinical trial selection timelines while maintaining absolute compliance with global patient privacy standards.
Retail and E-commerce
Modernized open Lakehouse architectures allow large retail organizations to run dynamic, real-time pricing engines that adjust across thousands of SKUs based on immediate competitor activity and local inventory levels. Furthermore, unified supply chain data products allow predictive AI models to optimize warehouse logistics ahead of regional demand shifts.
Manufacturing and Telecommunications
High-velocity streaming data ingestion layers capture machine telemetry from factory floors or cell towers instantly. These continuous event streams feed edge AI models that predict equipment failures weeks before they happen, preventing incredibly expensive production line downtime.
Why Partner with Ness for Cloud Data Modernization
Building a resilient, high-throughput modern data estate that actively powers enterprise artificial intelligence requires deep specialized expertise. Monolithic global system integrators often rely on rigid, infrastructure-heavy lift-and-shift patterns that leave organizations burdened with high costs and inflexible systems.
Ness takes a fundamentally different, engineering-first approach.
The Ness Data Engineering Edge
| Legacy Systems Integrators | Ness Engineering Methodology |
| Single-cloud provider bias Often pushes a single, specific vendor’s ecosystem, leading to rigid architectural setups and potential lock-in. | True platform-agnostic design Delivers flexible architectures optimized across AWS, Azure, and Google Cloud based purely on your business needs. |
| Focuses on simple VM migration Treats the project as a standard lift-and-shift, moving legacy databases to cloud virtual machines without updating the structure. | Focuses on open lakehouses & mesh Architects decentralized data mesh frameworks and open lakehouses to eliminate data silos and unlock real-time intelligence. |
| Manual, slow governance setup Relies on static documentation, spreadsheets, and bureaucratic review boards that create development bottlenecks. | Automated, pipeline-native controls Embeds automated compliance, sensitive data masking, and immutable lineage tracking directly into the continuous deployment pipeline. |
| Delivers infrastructure containers Hands over a collection of basic, operational cloud infrastructure pieces that still require heavy data tuning. | Delivers production-grade AI estates Engineers high-throughput, context-rich, and validated ecosystems purpose-built to immediately power enterprise GenAI and agentic workflows. |
Ness pairs platform-agnostic delivery across AWS, Azure, and Google Cloud with deep domain experience operating within highly regulated industries like BFSI and healthcare. We know that data security, lineage, and compliance are non-negotiable architectural layers that must be engineered straight into the codebase from day one.
Our specialized, battle-tested AI-ready data modernization methodology ensures your organization does not just copy data from one storage disk to another. We fundamentally reconstruct your data landscape into a high-performance, context-rich environment purpose-built to execute advanced corporate AI at scale.
Building a truly intelligent enterprise demands far more than buying a software license or shifting your servers. It requires a dedicated data engineering partner.




